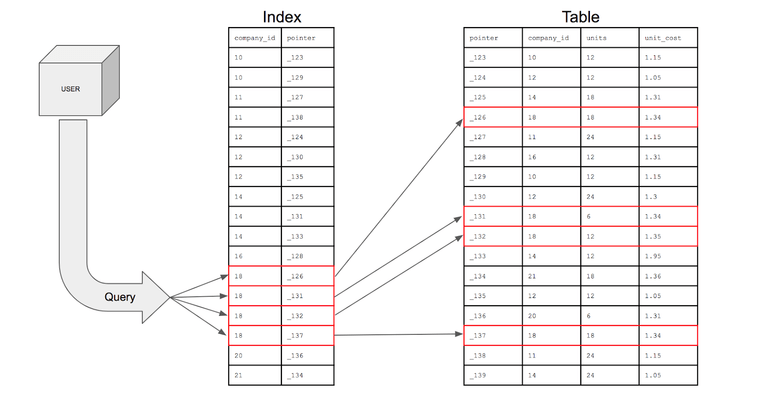
인덱스(Index)란 데이터베이스 테이블에서 데이터를 빠르게 검색할 수 있도록 도와주는 자료구조이다.
인덱스는 테이블의 특정 컬럼에 대해 별도의 데이터 구조(주로 B-Tree, Hash 등)를 만들어, 전체 테이블을 일일이 탐색하지 않고도 원하는 데이터를 빠르게 찾을 수 있게 해준다.
SQL에서 인덱스는 다음처럼 생성, 삭제, 재구성이 가능하다.
sql
CREATE INDEX 인덱스명 ON 테이블명(컬럼명); -- 인덱스 생성
DROP INDEX 인덱스명; -- 인덱스 삭제
ALTER INDEX 인덱스명 REBUILD; -- 인덱스 재구성
데이터베이스는 기본적으로 전체 테이블을 순차 탐색(Full Table Scan) 한다.
인덱스를 사용하면 특정 조건(Where)에 맞는 데이터를 테이블을 풀 스캔하지 않고 INDEX → ROWID → TABLE 순으로 빠르게 접근하기 때문에 데이터들을 빠르게 찾을 수 있다.
(여기서 ROWID란 테이블에서 하나의 Row(행)가 물리적으로 저장된 주소 값이다.)
2. Index와 Table의 구조적 차이
[출처] mangkyu.tistory.com/96
구분
Table
Index
목적
데이터를 실제로 저장
데이터를 빠르게 찾기 위한 포인터 목록
저장형태
테이블스페이스 내 데이터블록에 로우(행) 단위 저장
테이블과 별도 공간에 Key + RowID 쌍 저장
구조
Heap Table, Cluster Table 등 다양한 구조
주로 B-Tree, Bitmap, Hash 구조
읽는 방식
전체 스캔 또는 인덱스를 통해 접근
인덱스 트리 탐색 → RowID로 테이블 접근
Table
이름, 컬럼, 제약조건 같은 구조를 설명하는 틀로, 데이터베이스 내부적으로 스키마 객체(USER_TABLES, DBA_TABLES) 같은 메타 정보로 관리된다. 실제로 디스크에 저장되는 테이블 데이터로 테이블 스페이스 -> 데이터파일 -> 데이터 블록으로 실제 값이 저장된다.
Index
별도의 저장 공간에 생성되며(B-Tree / Bitmap, Hash) 같은 구조를 사용하여 Key + RowID를 쌍으로 하는 포인터 형태로 테이블과 분리된 파일 안에 저장된다. DB가 데이터를 검색할 때 인덱스를 먼저 탐색하고 RowID를 통해 테이블에서 실제 데이터를 읽는다.
따라서 비유로 쉽게 Table이 책이라면, Index는 책의 목차라고 표현하는 것이다.
책은 실제 내용을 담고 있고, 목차는 찾기 위한 주소 목록이다.
인덱스가 없으면 전체 책을 처음부터 끝까지 읽어야 하지만, 인덱스가 있으면 바로 찾아갈 수 있다.
3. 인덱스의 종류와 동작 원리
🔹인덱스 종류
종류
설명
특징
B-Tree Index
가장 일반적인 인덱스. 범위 검색 가능
WHERE 조건에 적합
Unique Index
중복을 허용하지 않음
PK, Unique 제약조건에 사용
Composite Index
여러 컬럼을 묶어서 만든 인덱스
다중 조건 WHERE 최적화
Hash Index
해시값 기반. 정확한 값 검색에 적합
NoSQL에서 자주 사용
Bitmap Index
값 종류가 적고 중복 많은 컬럼용
DW, OLAP 환경에서 유용
Full-Text Index
텍스트 검색 특화
검색엔진, 게시판 검색 등
🔹인덱스 스캔
방식
설명
Full Scan
인덱스 전체 탐색
Range Scan
범위 조건에 맞는 값만 탐색
Unique Scan
고유 인덱스를 이용해 단일 Row 조회
Skip Scan
선두 컬럼 없이도 인덱스 탐색 가능
🔹B-Tree 동작 원리
[출처] coding-factory.tistory.com/746
인덱스 유형 중에서 가장 많이 사용하는 인덱스의 구조는B-Tree(균형 트리, Balanced Tree)구조이다.
B-Tree 기반으로 B+Tree 또는 B*Tree 형태로 변형하여 사용하기도 하며, B*Tree 인덱스는 오라클을 비롯한 대부분의 DBMS에서 사용하고 있는 보편적인 인덱스이다.
B-Tree는 루트 노드 → 브랜치 노드 → 리프 노드로 구성되어 있으며, 각 노드에는 데이터값과 해당 데이터가 실제 저장된 위치를 가리키는포인터가 함께 저장된다.
검색 시, 루트 노드에서 시작해 조건에 맞는 방향으로 브랜치를 따라 내려가고, 최종적으로 리프 노드에서 포인터를 통해 실제 데이터를 찾아내는 방식이다.
B-Tree는 BST(Binary Search Tree, 이진 탐색 트리) 와 비슷해 보이지만, BST는 노드당 자식이 최대 2개인 반면, B-Tree는 노드 안에 데이터가 n개 존재하면 자식 노드의 수는 항상 n+1개가 되는 구조이다. (초기 root의 경우나 leaf노드 제외)
따라서 B-Tree 자료구조가 균형 트리라고 불리는 이유는 값이 추가될 때마다 트리는 스스로 노드 분할(페이지 분할)을 통해 균형을 맞추고, 모든 리프 노드는 항상 동일한 깊이를 가지게 되기 때문이다.
클러스터형 인덱스(Clustered Index) = 오라클에서는 Index Organized Table(IOT)
보조 인덱스(Non-Clustered Index)
🔹클러스터형 인덱스 (Clustered Index, IOT)
일반적으로Index와 Table은 분리형이다. 인덱스에 먼저 접근해서 rowid를 찾고 rowid를 이용해 테이블에서 데이터를 다시 조회한다.
반면 Clustered Index(IOT)는 Table과 Index가결합된 형태로, 인덱스에 따로 접근할 필요 없이 테이블이 인덱스 순서대로 물리적으로 정렬된다.
테이블당 1개만 존재할 수 있으며 PK를 기준으로 자동 생성된다.
테이블 자체가 인덱스 구조로 만들어지기 때문에 검색 속도가 빠르지만 데이터를 삽입/수정/삭제할 때, 기존 데이터를 밀어내며 위치를 유지해야 하므로 성능에 영향을 준다.
예를 들어 ID 컬럼을 PK로 사용해 클러스터형 인덱스를 만들었다고 가정해보자, 이미 ID = 1,3,4 가 존재하는 테이블에 ID = 2를 삽입하면, 2보다 큰 모든 데이터는 한 칸씩 밀리고 ID = 2가 그 자리를 차지해야 한다. 데이터가 수십, 수백만 건이라면 이 과정은 엄청난 비용을 발생시킨다.
따라서 보통 Primary Key로는 순차적으로 증가하는 정수형 ID + Auto Increment 를 사용하는 이유이며, 새로운 데이터가 항상 맨 뒤에 추가되어 정렬 변경을 피할 수 있어 성능 저하를 방지할 수 있다.
⚠️ 오라클에서 사용하는 Cluster Index (Table)와는 다른 개념이다.
Cluster Index는 인덱스와 테이블이 느슨하게 연결된 구조로 인덱스와 데이터가 1:1이 아닌 1:N의 관계이다. 기존의 분리형 Index ↔ Table관계와, 일체형 Clurstered Index의 중간 역할을 하는 구조이다.
🔹보조 인덱스 (Non-Clustered Index)
Non-Clustered Index는 이름 그대로 클러스터형 인덱스가 아닌 일반 인덱스를 의미한다.
테이블 데이터와 인덱스가 분리된 형태로 저장되고, 인덱스의 리프 노드에는 실제 데이터를 찾기 위한 포인터(rowid) 가 저장된다.
보조 인덱스의 특징은 다음과 같다.
테이블 당 여러 개 생성 가능하다
데이터는 테이블에 저장되고, 인덱스는 데이터 위치(RowID)를 참조한다
조회 시 인덱스 + 테이블을 두 번 접근하므로 I/O가 발생한다
데이터가 삽입/수정/삭제될 때마다 인덱스도 별도로 갱신해야 한다
데이터 정렬을 보장하지 않는다
클러스터형 인덱스보다 삽입/수정/삭제 성능이 좋다
5. 장단점 및 주의 사항
장점
1️⃣ 검색 성능 향상
WHERE, JOIN, ORDER BY, GROUP BY 등에서 빠른 데이터 접근이 가능하다. 인덱스를 사용하면 선형 탐색(O(N)) 대신 로그 탐색(O(log N)) 또는 해시 기반 탐색(O(1))이 가능하다.
2️⃣ 정렬/그룹핑 최적화
인덱스 자체가 정렬된 구조라서 별도의 ORDER BY 없이도 정렬된 결과를 반환 가능하다.
단점
1️⃣ 쓰기 성능 저하
INSERT, UPDATE, DELETE시 테이블 뿐 아니라 인덱스도 갱신해야 하기 때문에 오버헤드 발생
2️⃣ 저장 공간 증가
인덱스는 테이블과 별개의 물리적 저장 공간을 차지한다. 컬럼 값이 길거나 Row 수가 많을수록 인덱스 크기도 커진다. 인덱스를 관리하기 위해 추가 관리가 필요하며 DB의 약 10%에 해당하는 저장 공간이 필요하다.
⚠️ 주의사항
인덱스는 잘 활용하면 성능을 크게 향상시키지만, 무분별하게 사용하거나 구조를 잘못 잡으면 오히려 성능을 떨어뜨릴 수 있다.
1️⃣ 인덱스를 과도하게 생성하면, DML(INSERT, UPDATE, DELETE) 작업 시 인덱스까지 함께 관리해야 하므로 쓰기 성능이 저하된다.
2️⃣WHERE조건으로 대부분의 데이터를 반환하는 경우, 옵티마이저는 인덱스를 사용하지 않고 Full Table Scan을 선택한다. 즉, 인덱스를 타지 않고 테이블 전체를 읽는 것이 더 빠를 수 있다.
3️⃣WHERE조건에 함수가 포함되면 인덱스를 사용할 수 없다.
sql
WHERE UPPER(NAME) = 'JOHN' // → 인덱스 무시
4️⃣인덱스는 내부적으로 정렬된 상태를 유지하기 때문에, 후방 일치 검색(LIKE '%abc')처럼 정렬 정보를 활용할 수 없는 경우 인덱스를 사용할 수 없다.
sql
WHERE JOB LIKE '%ist' -- 후방 검색, 인덱스 사용 불가
5️⃣복합 인덱스(Composite Index) 순서 주의
INDEX (A, B)는 WHERE A = ?일 때 효율적이나,WHERE B = ?만 사용하면 비효율적이다.
INDEX (A, B)가 다음과 같은 형태로 저장될 때
A
B
ROWID
1
a
...
1
b
...
1
c
...
2
a
...
2
d
...
3
b
...
sql
SELECT * FROM 테이블명 WHERE B = 'b'
B 값은 인덱스 내에서 A에 묶여있기 때문에 인덱스를 처음부터 끝까지 Full Scan해야 한다.
따라서 인덱스를 사용할 땐, 인덱스를 쓰는 목적과 기준을 다시 한번 생각해볼 필요가 있다.
6. 목적과 선택 기준
인덱스 쓰는 목적
조회 속도 개선: WHERE, JOIN, ORDER BY 속도 향상
정렬 최소화: 이미 인덱스가 정렬되어 있어 ORDER BY 시 별도 정렬 불필요
중복 체크: Unique Index를 통해 데이터 무결성 유지
인덱스 선택 기준
자주 WHERE, JOIN, ORDER BY, GROUP BY에 등장하는 컬럼
데이터 분포가 넓은 컬럼 <예: 성별(X), 사용자 ID(O)>
데이터가 10~20% 이상 WHERE로 추출될 경우 → Full Scan이 더 빠름
자주 검색/조인/정렬되는 컬럼에만 인덱스 생성: 불필요한 인덱스는 피함
저카디널리티 컬럼은 인덱스 비추천: 중복값이 많은 컬럼은 인덱스 효과가 적음
너무 넓은(large) 컬럼 인덱스는 피함: 인덱스 크기 증가로 오히려 성능 저하
적절한 인덱스 개수 유지: 읽기/쓰기 성능 균형 고려
인덱스를 사용할 때는 단순히 생성하는 것보다, 실제 쿼리가 어떻게 동작하는지를 확인하는 과정이 중요하다. 이를 위해 실행계획(Execution Plan) 을 반드시 확인해야 하며, 실행계획을 통해 쿼리가 인덱스를 제대로 사용하는지, 또는 Full Scan을 수행하는지를 사전에 파악하고 튜닝하는 습관이 필요하다.
ROW_NUMBER() 함수는 각 행에 고유한 순번을 부여하는 윈도우 함수로, 데이터 정렬, 순위 매기기, 페이징 처리 등에 사용된다.
정렬 기준이 필요하므로 ORDER BY와 필수로 사용되며 그룹별로 순번을 따로 지정하고 싶은 경우 PARTITION BY를 선택적으로 사용할 수 있다.
sql
SELECT
EMPNO, ENAME, SAL,
ROW_NUMBER() OVER (ORDER BY SAL DESC)
FROM
EMP
2. OVER()
OVER()는 윈도우 함수를 사용할 때 필수 절로, 집합화된 row들의 정렬 순서를 지정하는 데 사용된다.
OVER()를 사용할 때는 ORDER BY 절을 사용하여 정렬 순서를 지정할 수 있다.
ORDER BY 절은 출력되는 로우의 순서와 일치하지 않아도 된다.
sql
SELECT
DEPTNAME,
EMPNO,
SAL,
RANK() OVER (PARTITION BY DEPTNAME ORDER BY SAL DESC)
FROM
EMP
3. PARTITION BY
PARTITION BY는 데이터를 그룹으로 분할하여 계산하는 데 사용된다. 마치 GROUP BY처럼 동작하지만, 집계하지 않고 원본 데이터를 유지하면서 그룹 내에서만 순번이나 계산을 적용할 수 있다.
즉, GROUP BY는 그룹화된 데이터 묶음을 집계함수를 이용하여 필요한 값을 계산하고, 이를 하나의 행으로 집약시키지만, PARTITION BY는 계산된 값을 그룹화된 데이터의 각각 행에 모두 별도의 컬럼으로 추가한다.
예시 1. GROUP BY - 부서 별 평균 급여
sql
SELECT
DEPTNO,
AVG(SAL) AS AVG_SAL
FROM
EMP
GROUP BY
DEPTNO
- DEPTNO가 10, 20, 30이면 3행만 출력됨 (요약된 값)
예시 2. PARTITION BY - 부서별 평균 급여를 모든 행에 표시
sql
SELECT
EMPNO, ENAME, DEPTNO, SAL,
AVG(SAL) OVER(PARTITION BY DEPTNO) AS AVG_SAL
FROM
EMP
4. Trouble Shoot
실무 중 입금 내역을 조회하는 화면에서 약정금이 중복으로 표시되고 집계되는 문제가 있었다.
하나의 약정금에 대해 입금이 여러 차례 나눠서 이루어지는 경우가 있다.
이 경우 입금이 2번, 3번 나뉘어져 있다면, 같은 약정금이 2번, 3번 반복해서 조회되는 상황이 발생한다.
이로 인해 소계, 총합 계산 시에도 약정금이 실제보다 더 크게 집계되는 오류가 발생한다.
즉, 회차별로 한 번만 보여야 할 약정금이 입금 횟수만큼 반복되어 나오는 문제였다.
동일 회차의 입금 행 중 첫 번째 행만 약정금을 보여주고, 나머지는 0으로 처리하기 위해 Sheet 렌더링 과정에서 셀 병합(Merge) 처리 하려 했지만, 소계 열 생성 내부 메서드와 같이 동작하지 않았다.
또한, 조회 후 Js에서 후처리하는 방법으로 동일 회차의 약정금을 Merge 처리하도록 작성하였다. 시간 복잡도를 계산했을 때 O(n)이 걸림에도 내부적으로 DOM을 조작과 렌더링 관련 오버헤드 때문에 브라우저 성능 저하가 심하여 정상적으로 동작하지 않았다.
앞서 해결 방법들이 잘못됐다 생각이 들었고, 조회 SQL 단계에서 해결하는 것이 단순히 시각적으로 보정하는 것보다 데이터 자체를 논리적으로 통제할 수 있을 것이라 생각했고 다음과 같이 처리했다.
sql
SELECT
입금자, 품목, 구분, 회차, 입금액, 입금일, ...
CASE
WHEN ROW_NUMBER() OVER (
PARTITION BY 입금자, 품목, 구분, 회차, ...
ORDER BY 입금액 DESC, 입금일, ... ASC
) = 1 THEN 약정금
ELSE 0
END AS 약정금
FROM 입금내역
...
PL/SQL은 Procedural Language/Structured Query Language의 약자로, 데이터베이스에서 SQL을 확장하여 절차적 프로그래밍 기능을 제공하는 언어이다.
DECLARE 선언부, BEGIN 시작부, EXCEPTION 예외부, END 끝 등의 구조로 이루어져있다.
1.1 주요 특징
절차적 프로그래밍: 조건문(IF, CASE), 반복문(LOOP, WHILE), 예외 처리 등 절차적 요소를 포함하여 논리적인 흐름을 제어할 수 있다.
블록 구조: PL/SQL은 선언부(DECLARE), 실행부(BEGIN-END), 예외 처리부(EXCEPTION)로 구성된 블록 구조를 사용한다.
익명 블록(Anonymous Block)
저장 프로시저(Stored Procedure)
함수(Function)
패키지(Package)
SQL 통합: SQL 문과 함께 동작하며, 프로시저, 함수, 트리거 등을 정의하고 실행할 수 있다.
모듈화 및 재사용성: 패키지를 통해 관련 함수와 프로시저를 묶어 관리할 수 있어 코드의 재사용성과 유지보수성을 높일 수 있다.
파라미터 지원: IN, OUT, INOUT 파라미터를 사용하여 외부에서 값을 전달받거나, 실행 결과를 반환할 수 있다.
IN: 읽기 전용 입력 값 (기본값)
OUT: 프로시저 실행 후 결과 반환
INOUT: 입력 값도 받고 결과 값도 반환
1.2 CURSOR
Oracle이 SQL 문을 실행할 때 생성하는 메모리 공간인 Context Area에서 쿼리 실행 상태 정보, 결과집합, 처리 행 수 등의 정보가 저장되고 Cursor는 이 Context Area를 참조하여 데이터를 가져오는 도구이다.
Context Area : SQL 실행 결과(결과집합)와 실행 상태 정보를 저장하는 메모리 영역
Cursor : Context Area를 가리키고 데이터를 가져오는 도구
암시적 커서
sql
DECLARE
v_count NUMBER;
BEGIN
SELECT COUNT(*) INTO v_count FROM employees;
DBMS_OUTPUT.PUT_LINE('총 직원 수: ' || v_count);
END;
SELECT COUNT(*) 실행 → Oracle이 자동으로 Context Area 생성
Context Area에 결과값(COUNT(*)) 저장
v_count 변수에 저장 후 Context Area 자동 해제
⚡ 암시적 커서의 특징
Context Area를 자동 관리
SQL%FOUND, SQL%NOTFOUND, SQL%ROWCOUNT 같은 속성으로 상태 확인 가능
명시적 커서
sql
DECLARE
CURSOR emp_cursor IS SELECT emp_name FROM employees;
v_emp_name employees.emp_name%TYPE;
BEGIN
OPEN emp_cursor; -- Context Area 생성 및 결과 저장
LOOP
FETCH emp_cursor INTO v_emp_name; -- Context Area에서 한 행 가져오기
EXIT WHEN emp_cursor%NOTFOUND;
DBMS_OUTPUT.PUT_LINE(v_emp_name);
END LOOP;
CLOSE emp_cursor; -- Context Area 해제
END;
OPEN emp_cursor → Context Area 생성
FETCH emp_cursor → Context Area에서 한 행씩 가져옴
CLOSE emp_cursor → Context Area 해제
⚡ 명시적 커서의 특징
Context Area를 직접 관리해야 함
OPEN, FETCH, CLOSE 등을 사용
1.3 장단점
✅ 장점
성능 향상: SQL 문을 미리 컴파일하고 저장하여 실행 속도가 빠름
네트워크 트래픽 감소: DB 내에서 로직을 처리하여 애플리케이션과의 통신량 감소
보안 강화: 데이터베이스 내부에서 실행되므로 직접 SQL을 실행하는 것보다 보안이 강화됨
트랜잭션 제어 가능: COMMIT, ROLLBACK을 활용해 안정적인 트랜잭션 관리 가능
❌ 단점
유지보수 어려움: 비즈니스 로직이 DB에 집중되면 코드 관리가 어려워짐
디버깅 불편: 일반 애플리케이션 코드보다 디버깅 및 로깅이 어려움
이식성 부족: DBMS에 종속적이므로 다른 데이터베이스로 이전 시 코드 변경 필요
병목 발생 가능: DB 서버에서 많은 로직을 처리하면 서버 부하 증가
1.4 Example
sql
CREATE OR REPLACE PROCEDURE EXAMPLE."PEXC_EXAMPLE_Q"
(
p_example1 VARCHAR2 DEFAULT 'Q'
,p_example2 VARCHAR2
,p_example3 VARCHAR2
,RTN_CURSOR OUT SYS_REFCURSOR
)
IS
---------------------------------------------------------------------------------------------------------------------------
-- ▩▩ [ 1. 변수선언 ]
---------------------------------------------------------------------------------------------------------------------------
ERR_CODE NUMBER := -20009; -- ERROR 코드
ERR_MSG VARCHAR2(200); -- ERROR Message
USER_EXCEPTION EXCEPTION;
v_sql_query VARCHAR2(1000); -- 동적 SQL 저장 변수
v_table_name VARCHAR2(50); -- 테이블명 동적 결정 변수
v_count NUMBER; -- 데이터 존재 여부 체크용
BEGIN
---------------------------------------------------------------------------------------------------------------------------
-- ▩▩ [ 2. 수행전 Check Logic ]
---------------------------------------------------------------------------------------------------------------------------
-- 테이블 존재 여부 체크 (p_example1 기준)
SELECT COUNT(*) INTO v_count
FROM all_tables
WHERE table_name = UPPER('TABLE_EXAMPLE1');
IF v_count = 0 THEN
RAISE_APPLICATION_ERROR(-20001, 'TABLE_EXAMPLE1 테이블이 존재하지 않습니다.');
END IF;
---------------------------------------------------------------------------------------------------------------------------
-- ▩▩ [ 3. Business Logic 처리 ]
---------------------------------------------------------------------------------------------------------------------------
DBMS_OUTPUT.PUT_LINE('example');
-- 동적 테이블명 설정
IF p_example1 = 'Q' THEN
v_table_name := 'TABLE_EXAMPLE1';
ELSE
v_table_name := 'TABLE_EXAMPLE3';
END IF;
-- 동적 SQL 생성
v_sql_query := 'SELECT * FROM ' || v_table_name;
-- 반복문을 활용한 디버깅 메시지 출력
FOR i IN 1..3 LOOP
DBMS_OUTPUT.PUT_LINE('Loop iteration: ' || i);
END LOOP;
-- 동적 SQL 실행
OPEN RTN_CURSOR FOR v_sql_query;
---------------------------------------------------------------------------------------------------------------------------
-- ▩▩ [ 4. Exception 처리 ]
---------------------------------------------------------------------------------------------------------------------------
EXCEPTION
WHEN USER_EXCEPTION THEN
RAISE_APPLICATION_ERROR(ERR_CODE, ERR_MSG);
WHEN OTHERS THEN
RAISE_APPLICATION_ERROR(ERR_CODE, SQLERRM);
END;
예시 구조를 보면 PL/SQL 코드가, Business Logic을 처리하는 Service Layer와 데이터 접근을 담당하는 Repository의 역할을 함께 수행하며, 하나의 Method처럼 활용한다.
그럼 Java단에서는 ? 추가적인 전처리나 후처리 작업이 없다면 파라미터만 넘겨 리턴 받으면 끝이다.
PL/SQL 같은 프로시저 기반 개발 방식에서는 계층형 아키텍처나 객체지향 설계를 쓰지 않는다.
2. Procedure vs Java
먼저 간략히 말하자면 우리 회사는 Stored Procedure를 사용한다.
입사 후 첫 프로젝트를 마치며 프로시저의 단점을 너무 많이 느꼈고, 왜 객체지향 개발을 하지않을까 의문이 생겼다.
그렇게 프로시저 개발을 채택하는 이유와 Java 프로그래밍에 대한 차이를 찾아보던 중 도움되고 공감되는 글이있었고, 두 개발 방식의 차이를 잘 정리해놓아 가져와보았다.
🔹 기술적 차이
Java : 컴파일된 소스를 어플리케이션 서버에 배포하여 실행하는 객체지향 프로그래밍. 비교적 간단한 쿼리로 데이터를 조회한 후 자바 객체를 이용해 로직을 구현
Procedure : DB 서버에서 소스를 컴파일 후 실행하는 절차지향 프로그래밍. 쿼리 집합. 순차적으로 쿼리를 수행하여 로직 구현. 문법이 DBMS 마다 다르다.
🔹 성능/부하 관련
Java :
어플리케이션 서버의 사양에 영향이 크고 DB 서버 사양에 비교적 영향을 덜 받는다.
쿼리 성능 외에 네트워크 IO 횟수에도 영향을 받는다.
객체지향다운 구현과 단순하고 효율적인 쿼리를 사용하여 DB 접속 네트워크 I/O 횟수를 줄이는 것이 좋다.
수행 쿼리 로그를 콘솔과 파일로 남길 경우 그를 위한 추가 자원과 시간이 필요하다. 네트워크 I/O 보다 로깅이 더 많은 시간을 잡아먹는다. 최신 로깅 라이브러리가 지원하는 비동기 로깅을 고려해볼 수 있다.
캐싱 기법으로 동일 쿼리 재수행을 최소화할 수 있다.
멀티 쓰레드를 활용하여 성능 향상을 기대할 수 있다. 단, 데드락에 주의해야 함. 또한 스프링 트랜잭션 전파는 멀티 쓰레드에 적용되지 않는다는 것도 주의.
성능 이슈가 발생할 경우 로깅 파일 살펴보면 응답이 느린 쿼리를 찾아내기 쉽다.
Procedure :
DB 성능이 매우 중요하다. 그러므로 DBMS 선택도 중요하고 DB 서버 사양도 중요함.
로직이 복잡할 경우 복잡한 쿼리를 사용하게 되어 쿼리 작성 실력과 튜닝이 더욱 중요해짐.
트랜잭션 격리 수준에 따라 다르지만, 동일 쿼리 반복 수행시 실제로 데이터를 조회하므로 비효율적인 쿼리 수행이 많음.
프로시저 자체에서 멀티쓰레드를 지원하진 않지만, 어플리케이션에서 멀티 쓰레드로 프로시저를 실행할 수는 있다.
성능 이슈가 발생할 경우 프로시저 내에서 속도가 느린 쿼리를 찾아내기 어렵다. DB 관리자의 지원이 절대적으로 필요.
🔹 형상관리 (버전관리)
Java : IDE 툴을 통해 모든 소스가 SVN, GIT 등으로 형상 관리가 되고 그것이 그대로 서버에 배포되므로 변경 추적과 원복이 용이하다. 동시에 같은 소스를 다른 개발자가 따로 수정할 경우 conflict 오류가 발생하여 서로 알아채고 merge 하기 쉽다.
Procedure : 별도로 소스 변경 내역을 수동으로 백업하며 관리하여야 하고 그것이 DB 서버에 실제로 반영되었음을 보장하지 않으므로 변경 추적과 원복이 어렵다. 동시에 같은 소스를 다른 개발자가 따로 수정할 경우 아무런 오류 없이 나중에 컴파일된 소스가 반영되므로 서로 알아채기 어렵다.
🔹 배포관리
Java : 변경 소스를 반영하기 위해 어플리케이션 서버를 무중단 서버로 구축하거나 재시작 해야한다.
Procedure : DB 에서 프로시저 컴파일만 하면 되므로 권한이 있는 사람이면 아무 때나 수정 배포할 수 있다. 단, 어플리케이션 서버에서 콜하는 프로시저이고 파라미터 갯수나 타입 등이 바뀔 때에는 어플리케이션 소스도 변경 배포되어야 하므로 두 작업이 되도록 동시에 이루어지도록 타이밍을 잘 맞추어야 한다.
🔹 디버깅/테스트
Java : 개발자들이 개발시 사용하는 IDE 툴로 쉽게 디버깅이 가능하다. 로깅 설정으로 로그 파일을 남기면 실제 수행된 쿼리와 바인딩된 변수 확인이 가능하므로 운영 환경에서도 문제 추적이 용이하다. 소스 일부 테스트와 테스트 자동화가 용이하다.
Procedure : 디버깅 지원하는 DB 툴이 있어야 하며, 파라미터를 수동으로 입력하고 실행하여 디버깅을 해야 한다. 잘못된 파라미터 입력으로 버그나 오류가 발생했는데 애꿎은 프로시저만 디버깅하느라 삽질하는 경우가 종종 있다. DB 서버 자체에 쿼리 수행 로그가 남지만 개발자에게 접근 권한을 주는 경우는 거의 없으므로 운영 환경에서 문제 추적이 어렵다. 프로시저 내에 특정 부분만 테스트할 수 없고 프로시저 단위로 수행해야 하므로 테스트 자동화가 까다롭다.
🔹 에러 처리
Java : 다양한 추상화 기법으로 일관된 에러 메시지 생성과 처리가 용이함.
Procedure : 발생한 에러 메시지를 어플리케이션에 OUT 변수로 전달해야 한다. 경우에 따라 어플리케이션에서는 이를 다시 특정 Exception 으로 포장하거나 분기 처리해야 하므로 비교적 다루기 복잡함.
🔹트랜잭션 관리
Java : 스프링 등의 선언적 트랜잭션 관리 기법으로 코딩이 아닌 설정을 통한 다양한 트랜잭션 전략 활용 용이하고, 그에 따라 트랜잭션을 조건에 따라 다양하게 옵션화할 때도 동일한 소스를 수정없이 재사용할 수 있다. 단, 일부 특수한 트랜잭션 설정은 DBMS 에서 지원해주는 것만 가능하다.
Procedure : 기본적으로 어플리케이션에서 트랜잭션을 관리하지만, 프로시저에서 수동 커밋 롤백이 가능함. 프로그래밍적으로 직접 커밋 롤백 명령문을 작성해야 하므로 트랜잭션 분리 전략을 다양하게 활용하기 어렵다.
🔹 DB 의존도
Java : 특정 DBMS 특화 문법이나 함수 사용을 지양하고 표준 ANSI SQL 위주로 개발하면 DB 의존도를 최소화하여 변경 비용을 크게 줄일 수 있다.
Procedure : DBMS 마다 프로시저 문법이 다르므로 의존도가 매우 높다. 양이 많고 복잡하다면 한 번 프로시저로 개발하면 DBMS 변경이 현실적으로 거의 불가능하다.
🔹 소스 보안 (안티 리버싱)
Java : 자바 특성상 디컴파일이 쉽기 때문에 완벽한 비공개가 어렵다. 전문 상용 난독화 툴을 적용하면 분석이 거의 불가능하게 만들 수 있기는 하다.
Procedure : DBMS 에 따라 자체 제공하는 소스 암호화 방법이 있다. 그 외 접근 제한을 통해 소스를 보호할 수도 있다.
🔹 개발/수정 생산성
Java : 객체지향 개발 특성상 개발 초기에는 자바 소스를 여럿 작성해야 해서 시간이 걸리지만, 일단 개발이 완료되고 나면 수정 변경에 유연하고 견고한 시스템을 구축할 수 있다.
Procedure : 개발 초기에는 프로시저만 작성하면 되어 금방 만들 수 있지만, 절차 지향 특성상 로직이 복잡해지고 소스가 길어질수록 점점 수정 변경이 어려워지고 리스크가 커진다.
Spring Boot부터 시작해서 OOP, JPA로 개발을 배웠던 나로서는 PROCEDURE의 단점이 너무 많다고 느낀다.
동적 SQL이나 프로시저 내 임시 테이블을 이용한 로직, 새로운 프로젝트마다 덕지덕지 붙어서 돌아가는 SP들은 가독성도 좋지 않고, 디버깅이 힘들어 유지 보수 측면에서 너무 불편하다.
하지만 한편으론, 진짜 이런 방식이 ‘무조건 나쁜 걸까?’ 하는 생각도 든다.
과연 Java로 모든 로직을 옮기면 정말 더 깔끔하고 유지 보수하기 쉬운 구조가 될까?
10년 넘는 도메인 지식을 가진 설계자들이 반드시 Spring과 JPA를 잘 알아야 할까?
결국, 기술 선택에는 비용과 리소스, 그리고 누가 그것을 다룰 수 있느냐가 전부 포함되어 있다.
비즈니스 적으로도 모두 다 해당하는 개발자의 인건비와 빠른 개발 속도를 포기하고 Java를 택하기엔 수지 타산이 맞지 않다.
결국 중요한 건 "무엇이 더 낫냐"가 아니라, "이 상황에서 어떤 선택이 더 효율적인가?"라는 질문이다.
현재로서 내가 할 수 있는 일은 지금 쓰고 있는 구조 안에서 최대한 문제를 줄이는 것뿐.
이런 고민을 하다 보면, 나는 도대체 어떤 개발자가 되고 싶은 걸까 하는 질문에 자꾸 멈춰 서게 된다.
옛 방식을 고수하면 도태될까 두렵고, 그렇다고 무작정 신기술만 밀어붙이는 마이웨이 개발자가 되는 것도 싫다.
Mybatis에서 프로시저를 사용할 때는 statementType을 CALLABLE로 설정해야 한다. 반대로, 일반적인 SQL 쿼리를 실행하는 경우에는 statementType을 PREPARED로 설정해야 한다.
MyBatis에서 statementType은 SQL 실행 방식에 따라 세 가지 옵션을 제공한다.
STATEMENT: 일반적인 SQL 쿼리를 실행하며, 매개변수를 전달할 수 없다. 실행 시마다 컴파일되므로 성능이 떨어질 수 있지만, DDL 문(create, alter, drop 등)에서 주로 사용된다.
PREPARED: 사전 컴파일된 SQL을 실행하며 매개변수를 전달할 수 있다. 반복 실행 시 성능이 뛰어나고 SQL 인젝션을 예방할 수 있습니다. 일반적인 SELECT, INSERT, UPDATE, DELETE와 같은 동적 쿼리에 적합하다.
CALLABLE: 저장 프로시저를 호출하는 데 사용된다. 프로시저의 입력 매개변수와 출력 값을 설정할 수 있으며, 미리 컴파일되어 있어 성능상 이점이 있다. Oracle이나 SQL Server에서 저장 프로시저를 활용할 때 적합하다.
Select 속성
속성
설명
id
구문을 찾기 위해 사용될 수 있는 네임스페이스내 유일한 구분자
parameterType
구문에 전달될 파라미터의 패키지 경로를 포함한 전체 클래스명이나 별칭
parameterMap
외부 parameterMap을 찾기 위한 비권장된 접근방법. 인라인 파라미터 매핑과 parameterType을 대신 사용하라.
resultType
이 구문에 의해 리턴되는 기대타입의 패키지 경로를 포함한 전체 클래스명이나 별칭. collection인 경우 collection 타입 자체가 아닌 collection 이 포함된 타입이 될 수 있다. resultType이나 resultMap을 사용하라.
resultMap
외부 resultMap 의 참조명. 결과맵은 마이바티스의 가장 강력한 기능이다. resultType이나 resultMap을 사용하라.
flushCache
이 값을 true 로 셋팅하면 구문이 호출될때마다 로컬, 2nd 레벨 캐시가 지워질것이다(flush). 디폴트는 false이다.
useCache
이 값을 true 로 셋팅하면 구문의 결과가 2nd 레벨 캐시에 캐시 될 것이다. 디폴트는 true이다.
timeout
예외가 던져지기 전에 데이터베이스의 요청 결과를 기다리는 최대시간을 설정한다. 디폴트는 셋팅하지 않는 것이고 드라이버에 따라 다소 지원되지 않을 수 있다.
fetchSize
지정된 수만큼의 결과를 리턴하도록 하는 드라이버 힌트 형태의 값이다. 디폴트는 셋팅하지 않는 것이고 드라이버에 따라 다소 지원되지 않을 수 있다.
statementType
STATEMENT, PREPARED 또는 CALLABLE 중 하나를 선택할 수 있다. 마이바티스에게 Statement, PreparedStatement 또는 CallableStatement를 사용하게 한다. 디폴트는 PREPARED이다.
resultSetType
FORWARD_ONLY|SCROLL_SENSITIVE|SCROLL_INSENSITIVE|DEFAULT(same as unset)중 하나를 선택할 수 있다. 디폴트는 셋팅하지 않는 것이고 드라이버에 다라 다소 지원되지 않을 수 있다.
databaseId
설정된 databaseIdProvider가 있는 경우 마이바티스는databaseId속성이 없는 모든 구문을 로드하거나 일치하는databaseId와 함께 로드될 것이다. 같은 구문에서databaseId가 있거나 없는 경우 모두 있다면 뒤에 나온 것이 무시된다.
resultOrdered
이 설정은 내포된 결과를 조회하는 구문에서만 적용이 가능하다. true로 설정하면 내포된 결과를 가져오거나 새로운 주요 결과 레코드를 리턴할때 함께 가져오도록 한다. 이전의 결과 레코드에 대한 참조는 더 이상 발생하지 않는다. 이 설정은 내포된 결과를 처리할때 조금 더 많은 메모리를 채운다. 디폴트값은false이다.
resultSets
This is only applicable for multiple result sets. It lists the result sets that will be returned by the statement and gives a name to each one. Names are separated by commas.
affectData
Set this to true when writing a INSERT, UPDATE or DELETE statement that returns data so that the transaction is controlled properly. Also seeTransaction Control Method. Default:false
Insert, Update, Delete 속성
속성
설명
id
구문을 찾기 위해 사용될 수 있는 네임스페이스내 유일한 구분자
parameterType
구문에 전달될 파라미터의 패키지 경로를 포함한 전체 클래스명이나 별칭
parameterMap
외부 parameterMap 을 찾기 위한 비권장된 접근방법. 인라인 파라미터 매핑과 parameterType을 대신 사용하라.
flushCache
이 값을 true 로 셋팅하면 구문이 호출될때마다 캐시가 지원질것이다(flush). 디폴트는 false 이다.
timeout
예외가 던져지기 전에 데이터베이스의 요청 결과를 기다리는 최대시간을 설정한다. 디폴트는 셋팅하지 않는 것이고 드라이버에 따라 다소 지원되지 않을 수 있다.
statementType
STATEMENT, PREPARED 또는 CALLABLE중 하나를 선택할 수 있다. 마이바티스에게 Statement, PreparedStatement 또는 CallableStatement를 사용하게 한다. 디폴트는 PREPARED 이다.
useGeneratedKeys
(입력(insert, update)에만 적용) 데이터베이스에서 내부적으로 생성한 키 (예를들어 MySQL또는 SQL Server와 같은 RDBMS의 자동 증가 필드)를 받는 JDBC getGeneratedKeys메소드를 사용하도록 설정하다. 디폴트는 false 이다.
keyProperty
(입력(insert, update)에만 적용) getGeneratedKeys 메소드나 insert 구문의 selectKey 하위 엘리먼트에 의해 리턴된 키를 셋팅할 프로퍼티를 지정. 디폴트는 셋팅하지 않는 것이다. 여러개의 칼럼을 사용한다면 프로퍼티명에 콤마를 구분자로 나열할수 있다.
keyColumn
(입력(insert, update)에만 적용) 생성키를 가진 테이블의 칼럼명을 셋팅. 키 칼럼이 테이블이 첫번째 칼럼이 아닌 데이터베이스(PostgreSQL 처럼)에서만 필요하다. 여러개의 칼럼을 사용한다면 프로퍼티명에 콤마를 구분자로 나열할수 있다.
databaseId
설정된 databaseIdProvider가 있는 경우 마이바티스는databaseId속성이 없는 모든 구문을 로드하거나 일치하는databaseId와 함께 로드될 것이다. 같은 구문에서databaseId가 있거나 없는 경우 모두 있다면 뒤에 나온 것이 무시된다.